Die Nadel im Datenhaufen
| 12. Oktober 2016
Der von Maia Zaharieva und ihrem Team entwickelte Algorithmus erkennt eigenständig Bild- und Tonsequenzen, die zusammengehören. (Foto: Universität Wien)
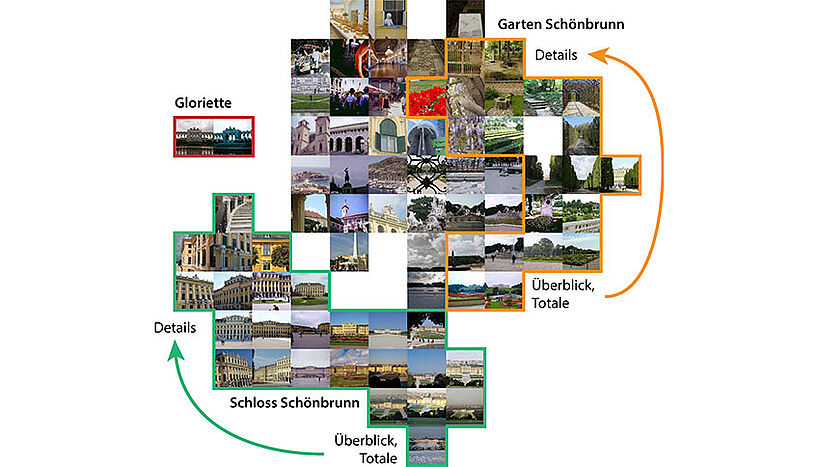
Ähnlich wie der Mensch kann der Algorithmus sich wiederholende Motive auch aus verschiedenen Perspektiven erkennen und miteinander verknüpfen. (Foto: Maia Zaharieva)
Im Zuge des digitalen Wandels eroberten soziale Medien und Smartphones unseren Alltag. Unmengen an neuem audiovisuellen Content werden täglich online verfügbar gemacht. Die Informatikerin Maia Zaharieva und ihr Team entwickeln Methoden, die in dieser Datenflut für Überblick und Ordnung sorgen.
Die immense Zunahme von Multimedia-Content in Videoportalen und privaten Videosammlungen stellt eine neue Herausforderung an die Organisation und Abfrage des Materials dar. Anbieter wie YouTube, Vimeo oder Facebook haben in vielerlei Hinsicht Interesse daran zu wissen, welche Inhalte NutzerInnen auf ihren Plattformen hochladen – beispielsweise, um Trends in ihrem Verhalten nachzuverfolgen oder um Material zu erkennen, das ihren Richtlinien widerspricht.
Große Online-Datenbanken verlassen sich – gezwungenermaßen – oft ausschließlich auf die von den NutzerInnen zur Verfügung gestellten Empfehlungen und Metadaten wie Titel, Interpret und Genre. Auch die KonsumentInnen sind darum von den mitunter ungenauen Angaben bzw. dem Geschmack anderer NutzerInnen abhängig. In dieser Datenmasse können unkonventionelle Ausreißer leicht untergehen.
Überblick im Chaos schaffen
Ziel des Forschungsprojekts "Unusual Sequences Detection in Very Large Video Collections" ist es, genau solche unkonventionellen und damit potenziell interessante Sequenzen in großen Mediensammlungen zu erkennen. Zu diesem Zweck entwickeln Projektleiterin Maia Zaharieva und ihr Team der Forschungsgruppe Multimedia Information Systems der Universität Wien in Kooperation mit der TU Wien Methoden, die Bild- und Tonmaterial von Videos eigenständig auf charakteristische Eigenschaften durchsuchen.
Dabei kommen verschiedenste Charakteristika in Frage: "Die Aufgabe ist es, aus jedem Video sogenannte Features zu extrahieren – also Eigenschaften, die die Videos ausmachen, wie Länge, Bewegung, Farbverlauf, Objekte, Musik, Sprache und so weiter", so die Informatikerin der Universität Wien.
Zunächst war viel Grundlagenforschung notwendig, um zu anwendbaren Prozessen zu gelangen: "Einerseits galt es zu erforschen, wie man von einer unbekannten Menge an Daten diejenigen Eigenschaften identifizieren kann, die typisch für diese Daten sind", erklärt Zaharieva. "Letztlich standen wir vor der Herausforderung, jene hochdimensionalen Features so zu analysieren, dass sogenannte Cluster entstehen, die die Inhalte bündeln oder eben Ausreißer freilegen."
Wie funktioniert der neue Algorithmus?
Ist eine Eigenschaft wie beispielsweise eine Bildregion, die im Wesentlichen nur ein Objekt enthält, im Video erkannt worden, markiert der Algorithmus alle weiteren Videosequenzen, in denen er auf dieses Objekt stößt. 
Wird etwa ein Schlagzeuger erkannt und als solcher benannt, kann der Algorithmus alle Videos innerhalb der Datenbank, die diesen oder einen ähnlichen Schlagzeuger enthalten, als Suchergebnis bereitstellen.

Der Algorithmus erkennt den Schlagzeuger nicht als Schlagzeuger, sondern als ein Objekt, das in der Bildabfolge zusammengehört. (Fotos: Maia Zaharieva)
Wiederkehrende Regionen
Weiters stellte sich das Team die Frage, wie man das komplexe, sich stetig verändernde Medium Video kompakt erfassen und auf einen Blick darstellen kann. Da jede Videosequenz mit mehreren, oft hoch-dimensionalen Eigenschaften assoziiert wird, ist eine Kernfrage des Projekts, wie eine Videosequenz repräsentiert werden kann, um Vergleich und Abfrage effizient zu ermöglichen. "Anders als bisher üblich orientiert sich unsere Methode nicht an Schlagwörtern der ContenterzeugerInnen – sondern an dem, was tatsächlich im Video zu sehen und zu hören ist", erläutert Maia Zaharieva.
Der Forschungszugang ist leicht verständlich: "Die Methode sucht nach Regionen im Video, die sich wiederholen – so wie Menschen sich an wiederkehrende Muster erinnern. Außerdem sucht der Algorithmus in sehr viele Richtungen nach Eigenschaften, weil er eben vorher nicht weiß, welche letztendlich typisch für das Video sind."

Was ist Ihre Antwort auf die Semesterfrage "Wie leben wir in der digitalen Zukunft?"
Maia Zaharieva: "Die enormen Datenmengen an sich bringen keinen Nutzen, wenn wir sie nicht verstehen und analysieren können. Auch die NutzerInnen spielen dabei eine zentrale Rolle. Sie werden heute oft durch vorgegebene, globale Filter in der digitalen Welt gelenkt. In der Zukunft ist eine aktivere Einbindung der NutzerInnen unausweichlich, um individuelle Interessen und Ziele besser befriedigen zu können. Dieses bessere Verstehen wird zu einer zeitnahen und fundierten Optimierung von Entscheidungen und Prozessen führen. Wie leben wir in der digitalen Zukunft? Dynamischer, flexibler und individueller."
Eine emanzipierte Methode
Die Methode ist auch deshalb neuartig, weil sie anders als der "State of the Art" der aktuellen Forschung angelegt ist: "Viele Forschungsprojekte versuchen, einen Algorithmus auf Objekterkennung zu trainieren – es wird ihm quasi beigebracht: 'Das ist ein Auto, finde es in anderen Videos.' Wir versuchen eben genau jenes Trainieren einzelner Features, die vorgegeben sind, zu umgehen, und stattdessen den Algorithmus komplett ohne Überwachung erkennen zu lassen, was wichtig ist", erklärt die Projektleiterin.
Zur Frage, ob bei dem Resultat ihrer Entwicklungen bereits von künstlicher Intelligenz gesprochen werden kann, äußert sich die Forscherin vorsichtig: "Die Vision ist eher, das Material eigenständig ordnen zu lassen. Der Algorithmus muss nicht zwangsläufig verstehen, was das Objekt bedeutet. Trotzdem bemerkt er die Relevanz." (hma)

Das Team um Maia Zaharieva nimmt seit einigen Jahren an der internationalen Initiative MediaEval teil, die sich für Vergleichbarkeit wissenschaftlicher Ergebnisse im Multimediabereich einsetzt. In den vergangenen Jahren war Maia Zaharieva bei diesem internationalen Wettbewerb in unterschiedlich zusammengesetzten Teams sehr erfolgreich. (Foto: Universität Wien)
Das WWTF-Projekt "Unusual sequences detection in very large video collections" läuft von 1. Oktober 2012 bis 30. September 2016 unter der Leitung von Dr. Maia Zaharieva von der Forschungsgruppe Multimedia Information Systems (MIS) der Fakultät für Informatik und in Kooperation mit der Technischen Universität Wien, Institut für Softwaretechnik und Interaktive Systeme.
Verwandte Artikel:

02.02.2016

